[GCP-9] BigQuery
0. 지난 글
[GCP-1] 구글 클라우드 기본 개념
[GCP-2] 구글 클라우드 실습 준비
[GCP-3] 구글 클라우드 IAM
[GCP-4] Compute Engine
[GCP-5] VPC
[GCP-6] Cloud Load Balancing
[GCP-7] Google Cloud Storage
[GCP-8] Cloud SQL
10. BigQuery
10.1 BigQuery란?
bigquery는 확장성이 뛰어난 구글의 기업용 서버리스 기반의 데이터 웨어하우스이다.
* 데이터 웨어하우스 : 축적된 데이터를 모아 관리하는 곳
대용량 Dataset(최대 몇 십억 개의 행)를 대화식으로 분석할 수 있는 웹 서비스이다.
표준 SQL을 지원한다.
ODBC, JDBC 드라이버 제공 -> 데이터를 쉽고 빠르게 통합할 수 있다.
초고속 SQL 쿼리 실행 가능하다.
스토리지와 컴퓨팅이 분리되어 있어 데이터 웨어하우스 용량 확장성이 좋다.
내부적으로 관리형 열 형식 스토리지, 대량 동시 실행, 자동 성능 최적화 기능을 제공한다.
google cloud storage, 구글시트, 구글 드라이브 등으로 손쉽게 데이터 읽을 수 있다.
인포매티카, 탈랜드 같은 기존 ETL 도구와 연동 지원한다.
* ETL 도구 : Extract, Transform, Load의 약자로 데이터 추출, 변환, 적재하는 도구를 말한다.
모든 배치와 스트리밍 데이터를 분석할 수 있고, 수집한 데이터를 실시간으로 캡처하고 분석해 통계를 항상 최신으로 유지한다.
BigQuery ML을 이용하면 SQL 쿼리를 통해 ML 모델을 학습시키는 것이 가능하며, 클라우드 ML엔진과 텐서플로와도 통합이 가능하다.
10.2 BIgQuery 구조
projext > dataset > table
- project : 가장 큰 개념으로, 결제 및 승인된 사용자에 대한 정보가 저장되며 각 프로젝트에는 이름과 고유 ID가 있다.
- dataset : RDB의 database와 같은 개념으로, dataset은 특정 프로젝트에 포함되며, 데이블과 뷰에 대한 액세스를 구성하고 제어하는 데 사용한다.
- table : 행으로 구성된 개별 레코드가 포함된다. 각 레코드는 칼럼으로 구성되며, 모든 테이블은 칼럼명, 데이터 유형, 기타 정보를 설명하는 스키마로 정의된다.
- 기본 테이블 : BigQuery Repository에서 지원되는 테이블
- 외부 테이블 :BigQuery 외부 Repository에서 지원되는 테이블
- 뷰 : SQL 쿼리로 정의된 가상 테이블
- job : 쿼리, 데이터 로딩, 생성, 삭제 등 작업에 대한 단위
10.3 BigQuery SQL
BigQuery SQL 종류
- standard SQL
- legacy SQL
10.3.1 standart SQL VS legacy SQL
| Standard SQL | legacy SQL |
| '프로젝트명, 데이터세트, 테이블명' EX) select * from 'my-project.my-dataset.my-table' |
[프로젝트명:데이터세트,테이블명] EX) select * from [my-project:my-dataset,my-table] |
| 'with'절 사용 가능 | |
| DML(insert, update, delete)사용 가능 | |
| Array 및 Struct 데이터 타입 사용 가능 | |
| 더 엄격한 Timestmp 값 범위 | |
| 모든 위치에서 Sub Query 지원 |
10.3.2 표준 SQL 데이터 타입
참고 : https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types
데이터 유형 | BigQuery | Google Cloud
의견 보내기 데이터 유형 이 페이지에서는 값 도메인에 대한 정보를 포함하여 모든 Google 표준 SQL 데이터 유형을 간략히 설명합니다. 데이터 유형 리터럴 및 생성자에 대한 자세한 내용은 어휘
cloud.google.com
10.3.3 표준 SQL 쿼리
참고 : https://cloud.google.com/bigquery/docs/reference/standard-sql/query-syntax
쿼리 구문 | BigQuery | Google Cloud
의견 보내기 쿼리 구문 쿼리 문은 테이블 또는 표현식을 한 개 이상 검색하고 계산된 결과 행을 반환합니다. 여기서는 BigQuery의 SQL 쿼리에 관한 구문을 설명합니다. SQL 구문 query_statement: query_expr
cloud.google.com
* SubQuery : 쿼리 안에 또 다른 쿼리를 넣을 수 있는 기능
ex) SELECT TEMP.* FROM ( SELECT * FROM 'my-project.my_dataset.product') AS TEMP
* CROOS JOIN : 공통 필드가 없을 때 두 테이블을 합치는 기능
ex) SELECT * FROM 'my-project.my_dataset.product' CROSS JOIN 'my-project.my_dataset.access_log'
* INNER JOIN : On 또는 USING에서 지정한 칼럼을 기준으로 테이블을 합치며, 양쪽 모두 이쓴ㄴ 컬럼을 기준으로 데이터를 합치는 기능
* LEFT JOIN : USING에서 지정한 컬럼을 기준으로 테이블을 합친다. 왼쪽에 지정한 테이블을 기준으로 오른쪽에 데이터가 없으면 오른쪽에 지정한 테이블에 null을 넣는다.
* FULL JOIN : USING에서 지정한 컬럼을 기준으로 테이블을 합친다. 합치는 테이블의 매칭 되는 데이터가 없으면 양쪽 다 null을 넣는다.
10.3.4 표준 SQL 함수
참고 : https://cloud.google.com/bigquery/docs/reference/standard-sql/syntax
10.4 BigQuery ML
BigQuery ML을 사용하면, BigQuery에서 Python이나 자바와 같은 프로그래밍 언어 없이 표준 SQL 쿼리만으로 머신 러닝 모델을 만들고 실행할 수 있다.
다음 모델을 지원한다.
- 선형 회귀 : 숫자 값을 예측
- 이진 롤지 스틱 회귀 : 두 클래스 중 하나를 예측하는 데 사용
- 다중 클래스 로지스틱 회귀 : 3개 이상의 클래스를 예측하는 데 사용
장점
- python이나 자바와 같은 프로그래밍 언어를 사용하지 않고, sql을 사용해 모델 만들고 실행할 수 있다.
- 데이터 웨어하우스 내에서 모델을 만들고 실행하기 때문에 데이터를 내보내지 않아도 되어 속도가 빠르다.
10.5 BigQuery GIS
지리 데이터 유형과 표준 SQL 지리 함수를 사용하여 BIgQuery에서 지리공간 데이터를 분석화, 시각화할 수 있다.
제약사항
- 지리 함수는 표준 SQL에서만 지원한다.
- BigQuery Client library는 아직까지는 지오그래피 데이터 유형을 지원하지 않는다.
- DML문은 GEOGRAPHY 데이터 유형을 지원하지 않는다.
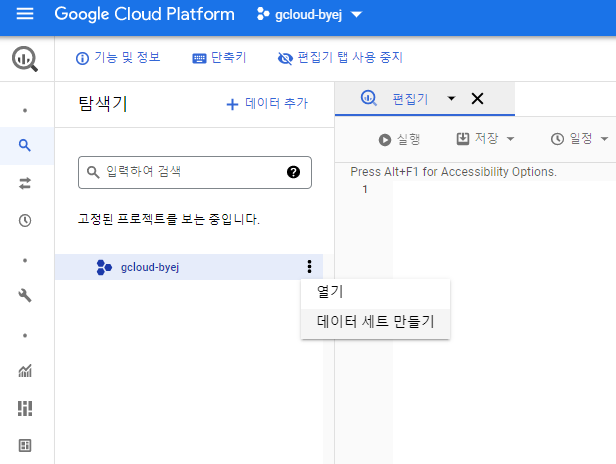
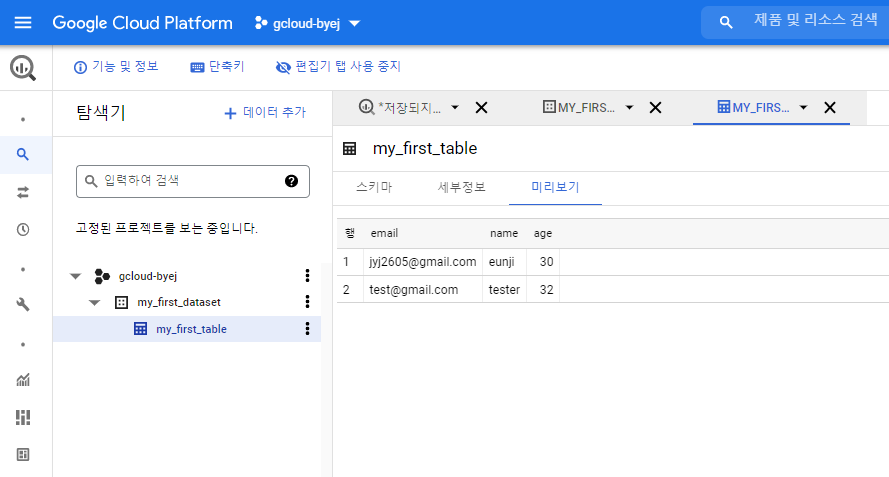
[실습 10.1 - 데이터 세트 및 테이블 생성 및 삭제]

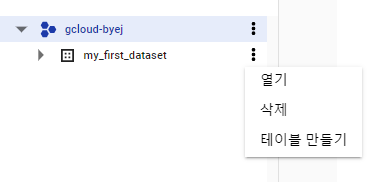


실행 명령어 :
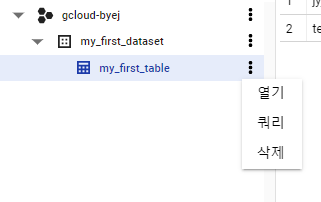
테이블을 삭제해 보자

* 실습 도중 아래와 같은 에러가 날 때가 있다.

그럴 땐 L옆 옆에 있는 ' 문자가 아니라 Esc아래 있는 ` 이 문자를 이용해서 쿼리를 작성해 보면 해결된다.

[실습 10.2 - CSV로 테이블 만들기]
csv 파일 샘플을 아래 링크에서 받는다.
https://eforexcel.com/wp/downloads-16-sample-csv-files-data-sets-for-testing/
Downloads 16 - Sample CSV Files / Data Sets for Testing - Human Resources (5 million records) - E for Excel
Disclaimer – The datasets are generated through random logic in VBA. These are not real human resource data and should not be used for any other purpose other than testing. Other data sets – Sales Credit Card Bank Transactions HR Analytics
eforexcel.com



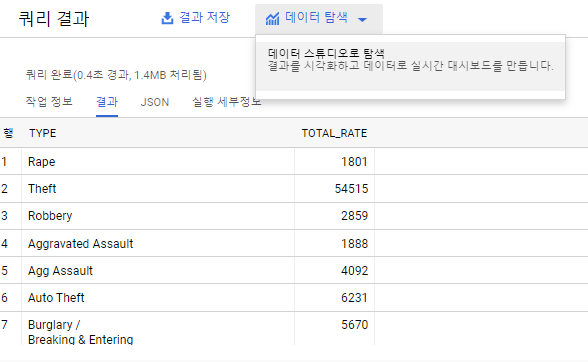
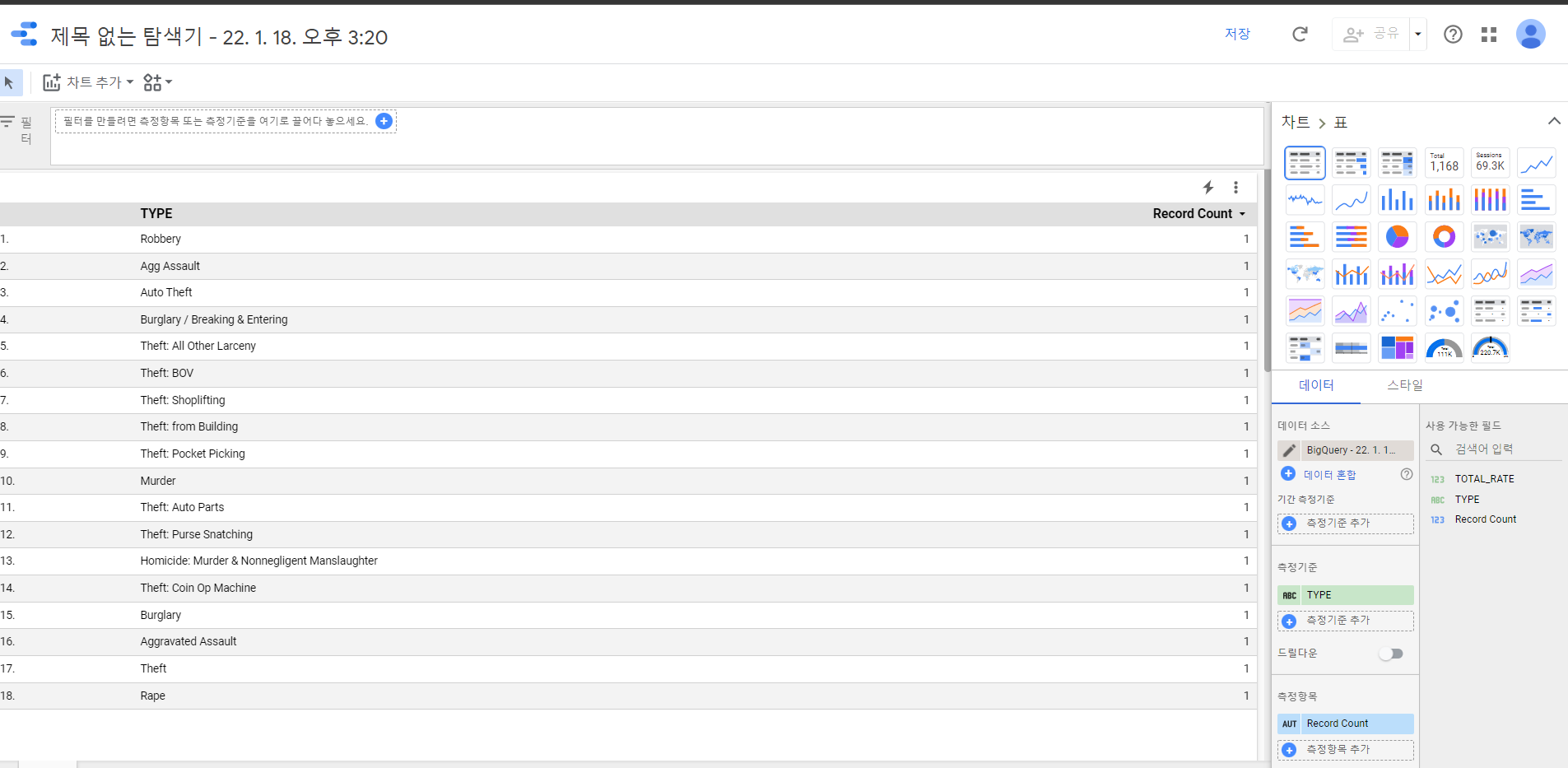
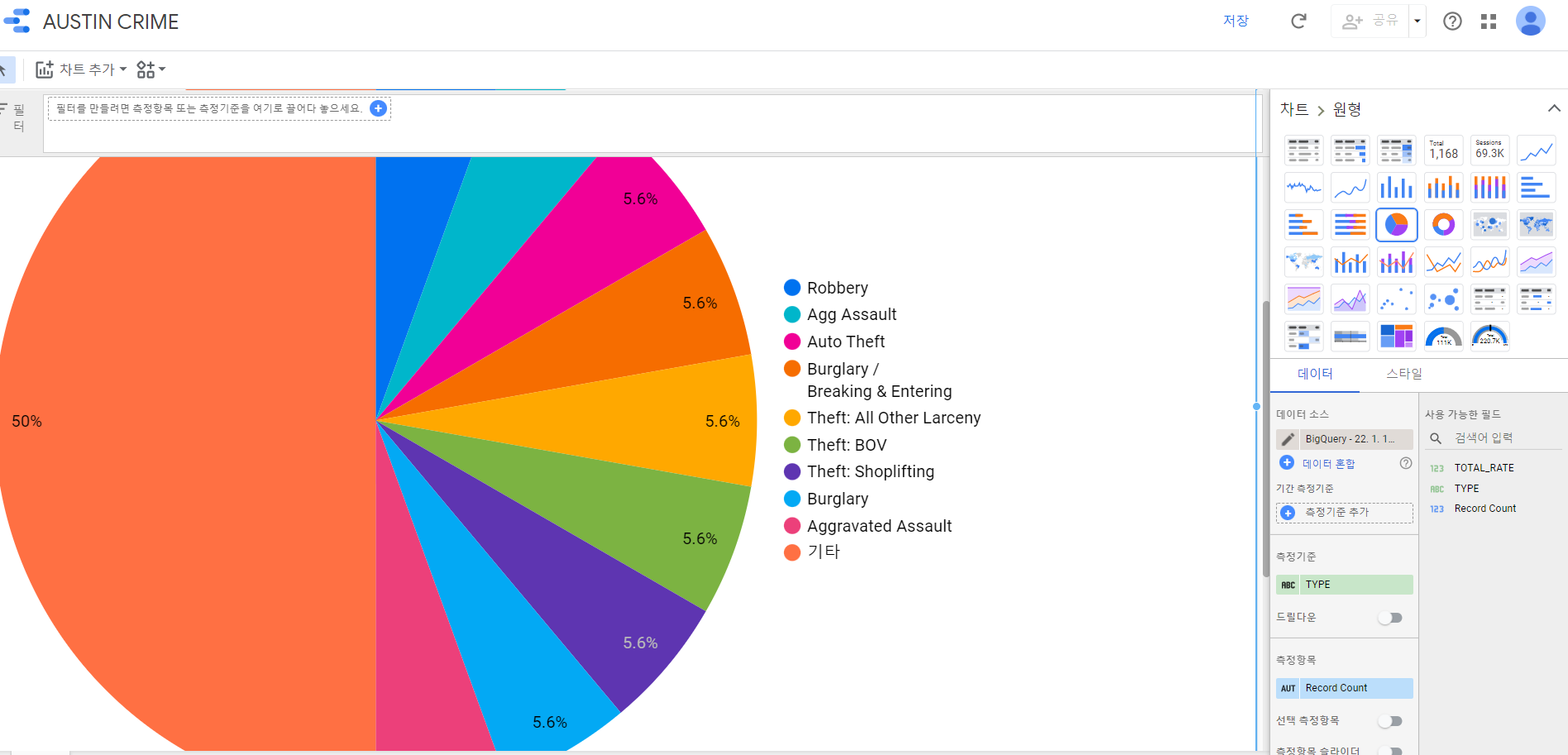
[실습 10.3 - 간단한 SQl 및 시각화와 저장]
BigQuery에서 제공하는 공개 데이터를 이용하여 간단한 SQL 작성을 통한 결과로 이를 시작화 및 저장을 해보겠다.
먼저 공개 데이터를 가져와보자



이제 범죄별 카운트를 구해보겠다.

실행 명령어 :